Understanding Database Indexes: The Backbone of Fast Data Retrieval

Indexes are one of the most critical concepts for databases, and if you're a backend engineer, understanding how they work under the hood is essential for optimizing performance. While database indexes share a similar concept to textbook indexes — both help retrieve data quickly — the similarities end there. Database indexes are much more complex and serve as one of the core mechanisms to speed up data queries.
In this blog post, we’ll dive deep into the mechanics of database indexes, why they are essential, and what trade-offs come with their usage. By understanding these core concepts, you’ll be better equipped to design and maintain efficient databases, leading to faster applications and better performance.
What Are Database Indexes?
At their core, database indexes serve as data structures that help to retrieve data from a database quickly. Think of them as shortcuts that enable the database to locate information faster without having to scan through every record. In essence, they work similarly to a textbook index, where you find a topic of interest and then refer to the page number without reading the entire book.
However, while the concept is easy to grasp, the internal workings of database indexes are far more complex. They involve intricate data structures like B-trees, leaf nodes, and doubly linked lists that allow databases to store and retrieve large amounts of data efficiently.
Why Data Retrieval Is Slow Without Indexes
Before we dive into how indexes work, it's important to understand why retrieving data from a database can be slow, especially as databases grow in size.
1. The Data Doesn’t Always Fit in Memory
In modern databases, the required data often exceeds the available memory (RAM) of the system. This means that when a query is run, the database engine may need to load data from disk storage rather than retrieving it directly from memory. Disk storage is significantly slower than memory, which contributes to the latency in data retrieval.
2. Data is Spread Across Disk Storage
Another issue is that data on disk storage is often stored in a random order. In a large database, rows of data might not be stored contiguously, making it difficult and time-consuming to locate specific records. To retrieve a single piece of data, the system might need to scan a significant portion of the disk, which can take a lot of time.
These two factors make it crucial to implement indexes, which are designed to speed up this retrieval process.
How Do Indexes Work?
To improve performance, indexes provide a way to rearrange and order the data to make it more accessible without moving the actual data stored on the disk. Here’s how they work under the hood:
1. The Role of Indexes
Database indexes are data structures that store information about the location of records in a way that minimizes the time it takes to find the data. When a query is made, the index allows the database to locate the relevant records much faster than a full table scan.
However, this increased read performance comes with trade-offs. Indexes require additional storage and make write operations (like INSERT, UPDATE, and DELETE) slower, as the index must be updated whenever the underlying data changes.
2. Indexes Provide an Ordered Representation
Indexes provide an ordered representation of the data, independent of where that data is stored on disk. In the context of a relational database, an index is typically built on one or more columns of a table. When a column is indexed, the database creates a mapping between the values in that column and the rows in the table where those values are found.
For example, if you have a table with a column user_id and you create an index on that column, the database will maintain an ordered list of user_id values and their corresponding row locations. This ordered list is stored in a data structure known as a B-tree (discussed later) to allow for efficient searching.
The Basic Building Blocks of Indexes: Leaf Nodes
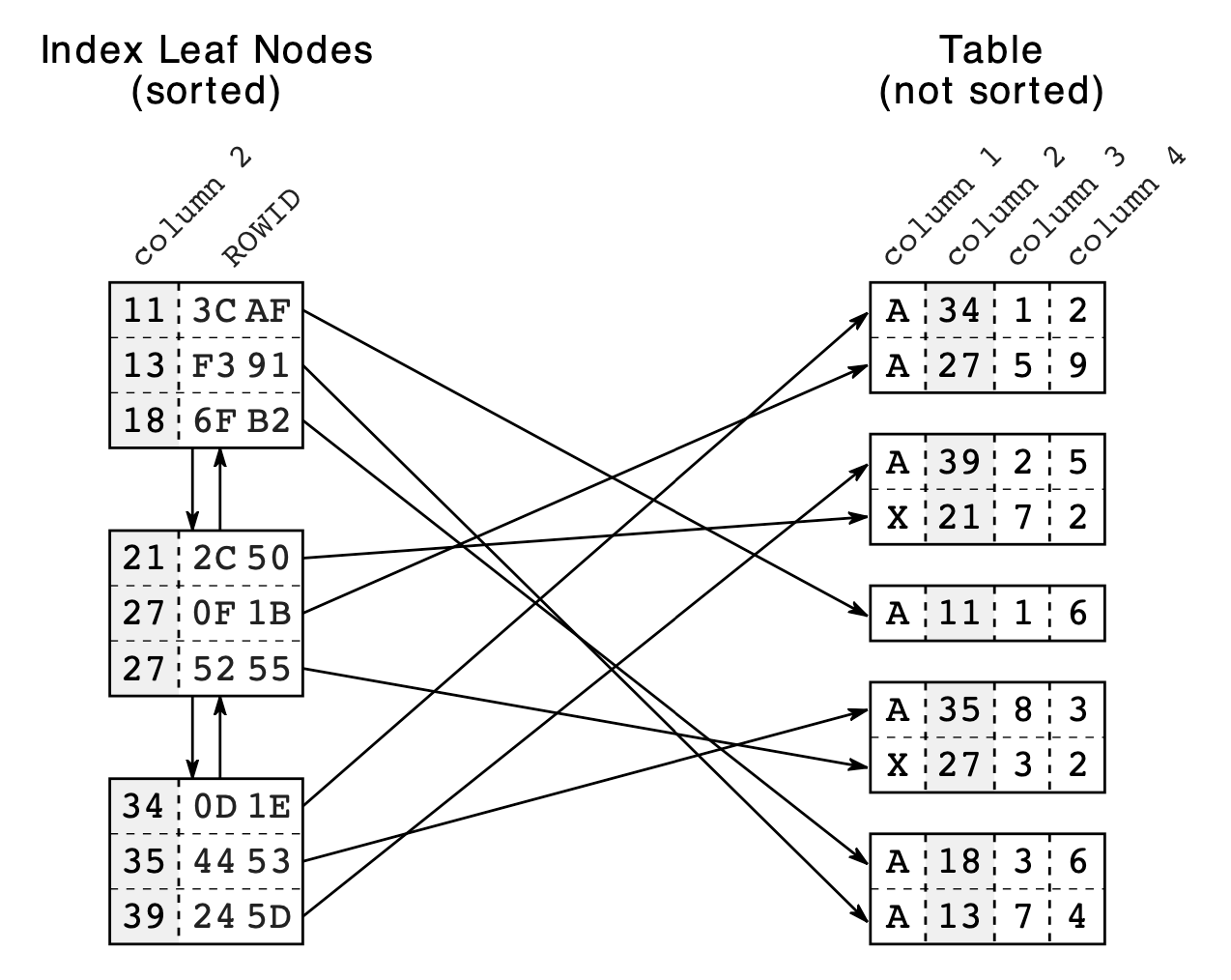
At the core of a database index are leaf nodes. Leaf nodes are the smallest components of the index and are responsible for storing the locations of the matching rows on the disk.
1. What Are Leaf Nodes?
When a column is indexed, the database doesn’t store the actual data in the index. Instead, it stores leaf nodes, which contain pointers to the locations of the actual data rows on disk. These nodes are organized in a way that makes searching through them fast.
2. Leaf Nodes Stored in Blocks
Databases store leaf nodes in their smallest block storage units. All blocks have the same size and can hold as many leaf nodes as possible. This ensures that the index itself remains compact and efficient to traverse.
To maintain order, a doubly linked list is established between the leaf nodes. This data structure ensures that the nodes can be read both forward and backward, offering flexibility during searches.
3. Advantages of Doubly Linked Lists
The doubly linked list offers two key advantages:
- Bidirectional Navigation: Nodes can be read both forward and backward, making certain types of searches (like
ORDER BY DESC) more efficient. - Efficient Updates: When adding or removing rows, only the pointers between nodes need to be updated, rather than reorganizing the entire index structure.
The Role of B-Trees in Indexes
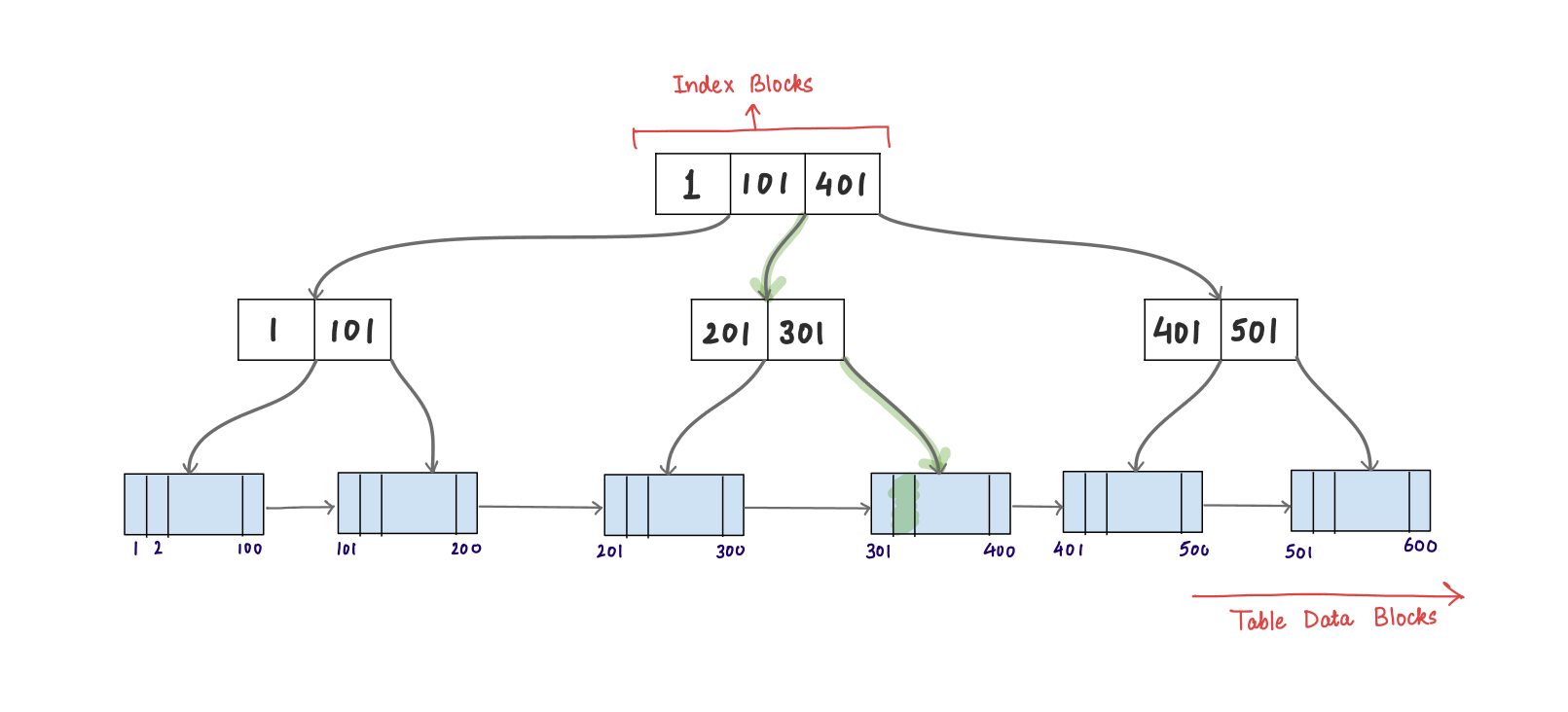
While leaf nodes are crucial for storing pointers to data, a secondary structure is needed to locate the correct leaf nodes efficiently. This is where B-trees come into play.
1. What Are B-Trees?
A B-tree is a self-balancing tree data structure used to store sorted data and allows searches, insertions, and deletions in logarithmic time. B-trees are used in most database systems to implement indexes because they handle large volumes of data efficiently.
2. B-Trees in Database Indexes
When a database uses a B-tree for its index, it organizes the data in a hierarchical manner. At the lowest level, you have the leaf nodes, which contain pointers to the actual rows in the table. The higher levels of the tree contain intermediate nodes that serve as guides to help the database find the correct leaf node.
Each intermediate node in the B-tree contains a reference to the highest value in its respective leaf nodes. By traversing down the tree, the database can follow a clear path to the appropriate leaf node that contains the pointer to the data you are looking for.
3. Balancing the B-Tree
One of the key features of B-trees is that they are balanced. This means that no matter how many records are added or removed from the database, the B-tree adjusts itself so that all paths from the root to the leaf nodes are of roughly equal length. This balance ensures that the performance of the index remains consistent, even as the dataset grows.
4. Exponential Growth, Logarithmic Depth
As the number of leaf nodes increases exponentially, the height of the tree grows logarithmically. This means that even if you have a massive dataset, the number of steps required to find the correct data remains relatively small. For example, even if a table has millions of rows, the database may only need to perform a few operations to locate the correct leaf node.
The Trade-offs of Using Indexes
While indexes are invaluable for improving the speed of data retrieval, they come with certain trade-offs that backend engineers need to consider.
1. Increased Storage Requirements
Indexes require additional storage space. The more columns you index, the more space is consumed by the index structures. In large databases, indexing multiple columns can significantly increase the storage footprint, so it’s important to be selective about which columns are indexed.
2. Slower Write Operations
Every time data is added, updated, or deleted from the database, the indexes must be updated accordingly. This means that operations like INSERT, UPDATE, and DELETE take longer when an index is involved. For databases with frequent write operations, this can become a performance bottleneck.
For example, if you have a table with multiple indexes and you perform an INSERT, the database will not only need to insert the new row but also update each index to account for the new data.
3. Trade-offs Between Read and Write Performance
The use of indexes involves a trade-off between read and write performance. While indexes significantly improve the speed of read operations, they can slow down write operations. For databases that prioritize fast reads (e.g., analytics databases), indexes are essential. However, for write-heavy databases (e.g., logging systems), you might need to be more cautious about over-indexing.
Best Practices for Using Indexes Effectively
Here are some key takeaways and best practices for using database indexes:
Index Selectively: Not every column needs an index. Focus on columns that are frequently used in WHERE, JOIN, and ORDER BY clauses.
Monitor Performance: Regularly monitor the performance impact of your indexes. Use database profiling tools to identify which queries benefit most from indexing and which ones don’t.
Be Mindful of Write Performance: If your application performs frequent writes, be cautious about adding too many indexes, as they can slow down INSERT, UPDATE, and DELETE operations.
Combine Indexes with Query Optimization: Indexes alone won't solve all performance problems. It's important to combine effective indexing strategies with well-optimized queries. Ensure that your queries are written in a way that takes full advantage of the indexes. For example, using LIKE '%term%' won’t benefit from indexes as much as LIKE 'term%' would. Additionally, avoid unnecessary SELECT * queries and retrieve only the columns you need.
Use Composite Indexes: In situations where queries filter or sort by multiple columns, consider using composite indexes. A composite index is an index on multiple columns, and it can significantly speed up queries that filter based on several criteria. For example, if you frequently query a table based on both user_id and created_at, you can create a composite index on (user_id, created_at) to optimize those queries.
Periodically Reevaluate Indexes: As your application evolves, the query patterns and data structure might change. Indexes that were helpful initially might become less effective or even detrimental over time. It’s important to periodically reevaluate your indexing strategy, especially as the database grows and new queries are introduced.
Use Indexes Sparingly on Write-Heavy Tables: If your application involves frequent write operations, such as logging or real-time data collection, be cautious about over-indexing. In such cases, consider using indexes only for the most critical queries or even using specialized database solutions like write-optimized databases (e.g., NoSQL databases).
Leverage Database-Specific Features: Many modern databases offer additional index-related features such as partial indexes, covering indexes, or unique indexes. Partial indexes can be useful for indexing only a subset of data, while covering indexes allow a query to retrieve all required data directly from the index, without having to access the table.
Types of Indexes: Understanding Your Options
There are several types of indexes available in most relational databases, and knowing when to use each type can greatly impact the performance of your queries. Here are a few common index types:
1. B-Tree Index
This is the default index type in most relational databases. B-trees are efficient for searching, inserting, and deleting data, and they maintain a balanced structure that allows for fast lookups. B-tree indexes are ideal for use with queries that filter using ranges, such as BETWEEN or >, and for ensuring ordered data in ORDER BY clauses.
2. Hash Index
A hash index maps values to a specific location in a hash table. Hash indexes are very fast for equality comparisons (e.g., = queries), but they are not suitable for range queries or sorting. They are typically used for primary key lookups in NoSQL databases or in situations where range lookups are unnecessary.
3. Full-Text Index
A full-text index is used to optimize queries that involve searching for words or phrases within text fields. This index type is commonly used for implementing search functionality in databases. Full-text indexes allow you to search for keywords in large text documents efficiently.
4. Bitmap Index
A bitmap index is designed for situations where a column has a low cardinality (i.e., a small number of unique values). Bitmap indexes are highly efficient for performing operations on columns that contain many repeated values, such as boolean or categorical fields.
5. Clustered Index
A clustered index determines the physical order of rows in the table based on the indexed column. Because the data is physically sorted, there can only be one clustered index per table. In most cases, the primary key of the table is used as the clustered index.
6. Non-Clustered Index
A non-clustered index doesn’t affect the physical order of data but creates a separate structure for fast lookups. You can have multiple non-clustered indexes on a table, and they are generally used for columns that are frequently searched or filtered, but are not the primary key.
When Not to Use Indexes
While indexes provide tremendous performance benefits, there are situations where adding an index may not be the best idea. Here are a few instances when you might want to avoid indexing:
1. Small Tables
For small tables, the overhead of maintaining an index may outweigh the benefits. When the entire table fits in memory, scanning the table might be just as fast as using an index. In such cases, adding an index may introduce unnecessary complexity.
2. Columns with High Cardinality and Frequent Updates
Indexes work best on columns with a wide range of unique values that are queried frequently. However, if a column contains highly dynamic data with frequent updates or insertions, indexing that column can lead to slower write performance due to the need to update the index constantly.
3. Highly Volatile Data
Tables that frequently undergo large batch updates or deletions may experience significant slowdowns if multiple indexes need to be updated in tandem. In such cases, it’s essential to strike a balance between read and write performance.
4. Sparse Query Patterns
If a column is rarely used in queries, indexing it will not provide any significant performance improvements and can even slow down write operations unnecessarily. For example, if you have an archived column that is rarely used in your queries, indexing it may not provide much value.
Conclusion: Indexes Are Critical, But Use Them Wisely
Indexes are a powerful tool for optimizing database performance, but they come with trade-offs that every backend engineer should understand. By decreasing the time it takes to retrieve data, indexes improve query performance, but they also require additional storage and can slow down write operations. Understanding how indexes work under the hood — particularly through structures like B-trees, leaf nodes, and doubly linked lists—is essential for building and maintaining efficient databases.
By using the right types of indexes and following best practices, you can significantly improve the performance of your database while minimizing the drawbacks. Whether you’re building a simple application or managing a large-scale system, mastering the art of indexing will ensure your application performs efficiently and scales well.